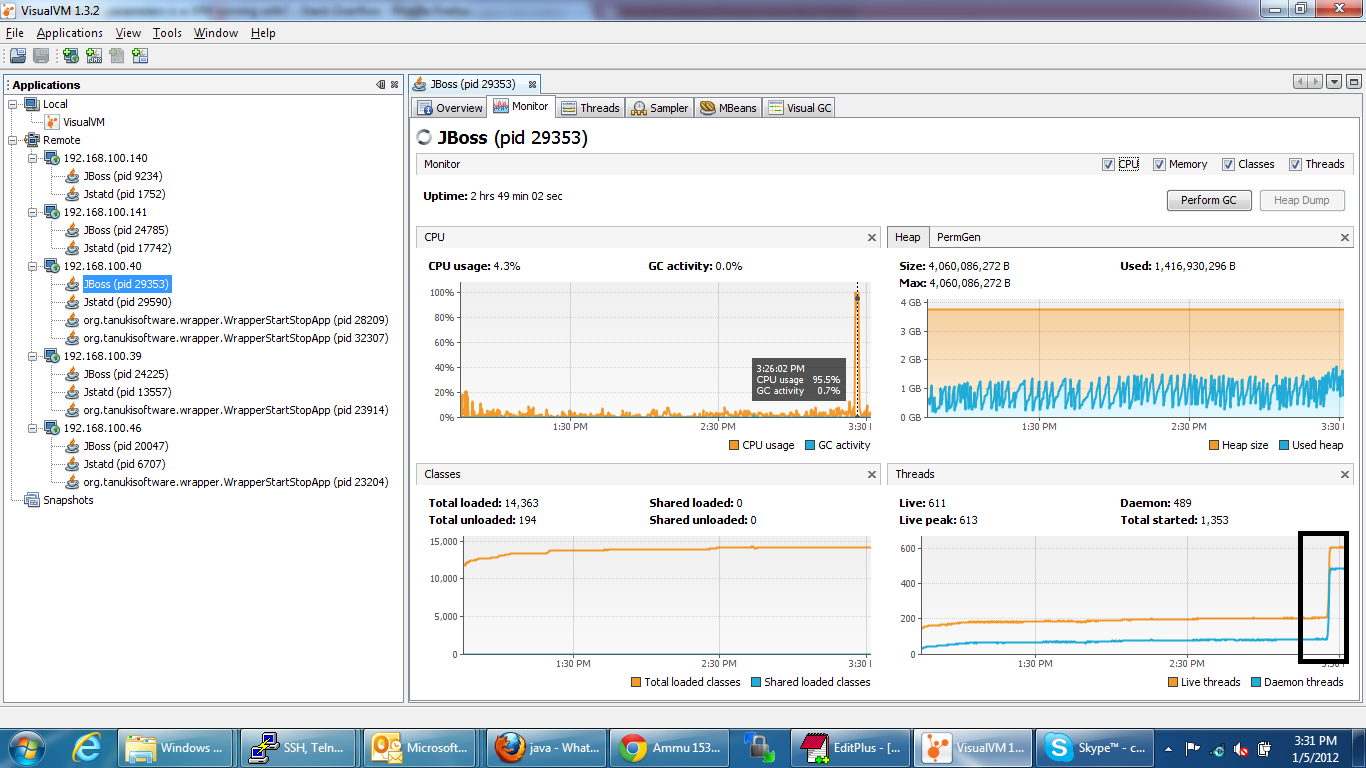
Cpu 100% and GC is running
Hi,
We have observered the CPU is touch 100% usage while GC running in JVM for couple of secs and (daemon)threads are increasing from 200 to 500.
Following are the GC logs:
2012-01-05T09:55:04.131000: 9748.990: [GC [PSYoungGen: 1269344K->24844K(1274944K)] 1644968K->410570K(3931200K), 0.1539430 secs]
2012-01-05T09:55:06.901000: 9751.760: [GC [PSYoungGen: 1266572K->16787K(1275200K)] 1652298K->412469K(3931456K), 0.1403010 secs]
2012-01-05T09:55:09.826000: 9754.685: [GC [PSYoungGen: 1258515K->28069K(1272640K)] 1654197K->427708K(3928896K), 0.0863350 secs]
2012-01-05T09:55:12.573000: 9757.432: [GC [PSYoungGen: 1267749K->28986K(1268672K)] 1667388K->442158K(3924928K), 0.1925500 secs]
2012-01-05T09:55:15.415000: 9760.274: [GC [PSYoungGen: 1268666K->29813K(1269760K)] 1681838K->456553K(3926016K), 0.1983170 secs]
2012-01-05T09:55:18.400000: 9763.259: [GC [PSYoungGen: 1263605K->25547K(1271232K)] 1690345K->465817K(3927488K), 0.0741820 secs]
2012-01-05T09:55:21.030000: 9765.889: [GC [PSYoungGen: 1259339K->28609K(1270464K)] 1699609K->479890K(3926720K), 0.0903450 secs]
2012-01-05T09:55:23.691000: 9768.550: [GC [PSYoungGen: 1262145K->23413K(1271104K)] 1713426K->486897K(3927360K), 0.0705770 secs]
2012-01-05T09:55:26.348000: 9771.207: [GC [PSYoungGen: 1256949K->20455K(1273152K)] 1720433K->492161K(3929408K), 0.0597660 secs]
2012-01-05T09:55:28.934000: 9773.793: [GC [PSYoungGen: 1257383K->25634K(1272448K)] 1729089K->504501K(3928704K), 0.0641520 secs]
2012-01-05T09:55:31.628000: 9776.487: [GC [PSYoungGen: 1262562K->24623K(1274304K)] 1741429K->513884K(3930560K), 0.0649770 secs]
2012-01-05T09:55:34.698000: 9779.557: [GC [PSYoungGen: 1263791K->34357K(1273536K)] 1753052K->531695K(3929792K), 0.0710200 secs]
2012-01-05T09:55:37.427000: 9782.286: [GC [PSYoungGen: 1273525K->32264K(1261248K)] 1770863K->550162K(3917504K), 0.0734510 secs]
2012-01-05T09:55:40.007000: 9784.866: [GC [PSYoungGen: 1258376K->36728K(1262848K)] 1776274K->572739K(3919104K), 0.0913590 secs]
2012-01-05T09:55:42.520000: 9787.379: [GC [PSYoungGen: 1262840K->21809K(1265728K)] 1798851K->578910K(3921984K), 0.0735170 secs]
2012-01-05T09:55:44.996000: 9789.855: [GC [PSYoungGen: 1243889K->21991K(1265024K)] 1800990K->585886K(3921280K), 0.0672800 secs]
2012-01-05T09:55:47.506000: 9792.365: [GC [PSYoungGen: 1244071K->25800K(1268032K)] 1807966K->597725K(3924288K), 0.0715630 secs]
2012-01-05T09:55:50.101000: 9794.960: [GC [PSYoungGen: 1251720K->20716K(1266560K)] 1823645K->603125K(3922816K), 0.0660460 secs]
2012-01-05T09:55:52.527000: 9797.386: [GC [PSYoungGen: 1246636K->17876K(1268672K)] 1829045K->606765K(3924928K), 0.0609200 secs]
2012-01-05T09:55:54.990000: 9799.849: [GC [PSYoungGen: 1246420K->22689K(1268544K)] 1835309K->615465K(3924800K), 0.0649620 secs]
2012-01-05T09:55:57.464000: 9802.323: [GC [PSYoungGen: 1251233K->16658K(1269824K)] 1844009K->617066K(3926080K), 0.0643570 secs]
2012-01-05T09:55:59.967000: 9804.826: [GC [PSYoungGen: 1247570K->15072K(1269760K)] 1847978K->619016K(3926016K), 0.0599230 secs]
2012-01-05T09:56:02.499000: 9807.358: [GC [PSYoungGen: 1245984K->16908K(1270400K)] 1849928K->623478K(3926656K), 0.0640130 secs]
2012-01-05T09:56:05.053000: 9809.912: [GC [PSYoungGen: 1248460K->13682K(1269824K)] 1855030K->625222K(3926080K), 0.0592950 secs]
2012-01-05T09:56:07.780000: 9812.639: [GC [PSYoungGen: 1245234K->7300K(1269056K)] 1856774K->623595K(3925312K), 0.0493350 secs]
2012-01-05T09:56:10.469000: 9815.328: [GC [PSYoungGen: 1238148K->5620K(1236480K)] 1854443K->623920K(3892736K), 0.0413330 secs]
2012-01-05T09:56:13.238000: 9818.097: [GC [PSYoungGen: 1236468K->7042K(1269248K)] 1854768K->627137K(3925504K), 0.0379700 secs]
2012-01-05T09:56:15.948000: 9820.807: [GC [PSYoungGen: 1236802K->7586K(1269184K)] 1856897K->629529K(3925440K), 0.0296320 secs]
2012-01-05T09:56:18.617000: 9823.476: [GC [PSYoungGen: 1237346K->10997K(1271104K)] 1859289K->635764K(3927360K), 0.0349820 secs]
2012-01-05T09:56:21.153000: 9826.012: [GC [PSYoungGen: 1243189K->9572K(1269760K)] 1867956K->638488K(3926016K), 0.0305350 secs]
2012-01-05T09:56:54.537000: 9859.396: [GC [PSYoungGen: 1241764K->11066K(1273536K)] 1870680K->642061K(3929792K), 0.0356580 secs]
2012-01-05T09:58:26: 9950.859: [GC [PSYoungGen: 1248058K->16924K(1272128K)] 1879053K->649544K(3928384K), 0.0543600 secs]
and my JVM settings are
-Dprogram.name=run.sh
-Dprogram.name=run.sh
-Xms3872m
-Xmx3872m
-Dsun.rmi.dgc.client.gcInterval=3600000
-Dsun.rmi.dgc.server.gcInterval=3600000
-XX:NewSize=1278m
-XX:MaxNewSize=1278m
-Djava.net.preferIPv4Stack=true
-XX:MaxPermSize=256m
-Djavax.net.ssl.trustStore=/opt/properties/.keystore
-Djavax.net.ssl.trustStorePassword=changeit
-Dcom.sun.management.jmxremote.port=8888
-Djava.rmi.server.hostname=xx.xx.xx.xx
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote
-XX:+PrintGCDetails
-Xloggc:/opt/gc.log
-XX:+UseTLAB
-Xss256k
Regards,
Arumilli.