Thoughts on RHQ-Alerts aka Alerts 2.0 aka Wintermute
Posted by pilhuhn in RHQ on Aug 13, 2014 9:44:24 AMWe have been thinking for a long time how to bring the Alerting from RHQ
- to a new level
- to other projects
For those who are less familiar with RHQ, I'll quickly describe the alerting possibilities: RHQ allows to alert on incoming metrics from monitoring and to compare the values with thresholds, possibly combining multiple metrics of a managed resource. Similar it is possible to trigger alerts on the outcome of resource operations, matched text in events (snmp traps, logfiles, ..), configuration changes and also changes in availability. Alerting can happen on single resources or group of resources and it is possible to define alerts on a template level, so that freshly added resources are directly enrolled into alerting. RHQ alerts have a few sorts of dampening to suppress duplicates when a problem persists and so on. For more information, you best consult the RHQ wiki.
Now while this is already quite powerful, there are numerous possibilities for enhancement like:
- comparing of two metrics with each other (used mem is > than 80% of total mem)
- comparing of metrics from different resources (if load balance is down or one of my 3 app servers in the cluster)
- temporary component in reasoning (if night and only 1/3 servers is down send email; if day always send text message ; default: send email and text message and make a phone call )
- finding an outlier in a group (if the load on one of my 3 boxes in the cluster is higher than on the others).
The RHQ-Wiki has a much bigger list.
As we have seen with RHQ-Metrics, there is also a similar need for alerting in other projects, which brings the same questions and thoughts on how to make Alerting available for them as well. Currently the thought go into the direction of also extracting alerting into its own project that can then be again pulled in into the next generation of RHQ and/or be used independently of RHQ.
The following graphic shows a possible architecture of this Alerting 2.0.
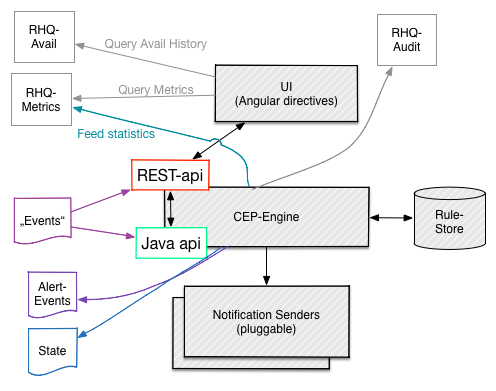
The core is would be a CEP (Complex Event Processing Engine) that offers a Java and REST-api (and perhaps messaging/JMS, feeding into the Java-api). The engine has a rule store, which could be a place in the Cassandra database of RHQ-metrics (each rule being a document) or for example just text files in git.
Modifications of the rules would work via the Engine and its APIs and would also be made available for auditing.
As with the current RHQ, there would be pluggable notification senders that do the sending of notification emails, txt messages, snmp traps and so on, just like in existing RHQ; we should in fact investigate how to best keep the existing senders or re-use hem with minimal effort.
Like in RHQ-metrics we will create and provide AngularJS directives for Alert-Definition-Editors to be re-used those directives may directly or indirectly also use other angular directives from e.g. RHQ-metrics to show a mini-graph of the metric so that the user can see the past values while defining the alert.
The most tricky part is probably a good composition of rules. We would support what we have today, which we could perhaps name "1-level" rules: they follow a "if (x and y) and not dampened then fire" pattern. In the future we would probably have more levels of rules like in this next (simple) diagram:
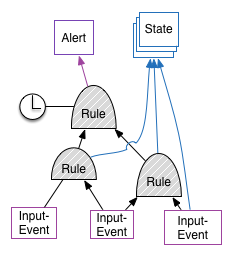
Input events would be correlated and then further processed into an alert and also into (resource) state. Resource state is similar to availability. We could even use this as the computed availability, where the incoming availability report from the resource is not taken literally, but processed by then engine. This allows to define computed availability as down when either the resource can not be pinged or requests take a minute to be processed.
A further rule can then take the time of day into account and see if the new state should end up in a notification to be created or not. Similar for any on-duty plans, where the notification is sent to the person on duty and not "randomly" to the whole operations group.
Depending on the severity another rule can define escalation handling: if the alert sent is not acknowledged within a certain amount of time, the engine would re-send the alert to the operation person or to a fallback person.
Ah and if you ask what this "Wintermute" in the subject is: go and read https://en.wikipedia.org/wiki/Neuromancer :-)
Comments