In this article, I will walk through an example, where I will show to move some data from CSV file into Apache Accumulo using Teiid. Then issue queries to Apache Accumulo, to get the contents of query using Teiid. Once the results are available in Teiid, you can further integrate/enhance this data with other data sources. Note that CSV was just an example, you could move data from any any RDBMS, webservice, XML or any custom sources. For keeping this example simple I choose importing the data from CSV file. The prerequisites for this example are to have some familiarity with Teiid and Apache Accumulo. For the purposes of this article I am using Teiid 8.7 (or later) and Apache Accumulo 1.5.0
Teiid documentation on Accumulo Translator can be found at Apache Accumulo Translator, I suggest you give this a read to understand the extension metadata properties that defined as part of this translator, and also import properties defined to import already defined data in Accumulo.
For the purpose of this example, I am using sample data from http://data.gov about baby names collected from social security numbers over the last century. The data is arranged by state. You can download data from http://catalog.data.gov/dataset/baby-names-from-social-security-card-applications-data-by-state-and-district-of- A copy of the file is attached (VA.txt). This ZIP file contains may different files, one file for each state with names of the babies with following format.
STATE, MALE or FEMALE, YEAR, NAME, # of babies KS,F,1910,Mary,251 KS,F,1910,Helen,172 KS,F,1910,Dorothy,144 ...
Unzip the "namesbystate.zip" file into any directory. For the purposes of this article I will assume this is unzipped into "/babynames" directory on your local machine.
The goal is load this data into Accumulo using Teiid, and issue queries against it using SQL. Note that, I am showing full example, where data is gathered from source system (CSV files) and loading of that data into Accumulo. Typically you may already have data in a RDBMS, Web Service etc. that needs to be loaded into Accumulo for querying. Step 1 will walk you through installing Accumulo on local machine, If you already have a Accumulo instance running, then skip to Step 2. However, you do need to copy some Teiid JAR files to all the Accumulo nodes and restart all nodes before you can proceed. You can find the details of the JAR files to copy at end of Step1.
Although translator might work with latest versions of the Apache Accumulo, Hadoop software, when developed this translator is tested with noted versions.
Step 1: Install and Configure Apache Accumulo
- Download Apache Zookeeper 3.4.5
- Download Apache Hadoop 2.2.0
- Download Apache Accumulo 1.5.0
- Download Apache Commons-Logging-1.1.3
Update: I also tested with Accumulo 1.6.4, Zookeeper 3.4.6, Hadoop 2.6.3 with out any issues. For Hadoop installation instructions see Apache Hadoop 2.7.2 – Hadoop: Setting up a Single Node Cluster. Use Teiid version 9.0 or DV 6.3 with this setup.
Install Apache Zookeeper ( instructions from http://zookeeper.apache.org/doc/trunk/zookeeperStarted.html)
[~/Downloads] $tar -zxvf zookeeper-3.4.5.tar.gz -C ~/testing cp ~/testing/zookeeper-3.4.5/conf/zoo_sample.cfg ~/testing/zookeeper-3.4.5/conf/zoo.cfg vi ~/testing/zookeeper-3.4.5/conf/zoo.cfg
Now edit the above zoo.cfg file, and make the "dataDir" property look like something below
dataDir=/home/{user}/testing/zookeeper-3.4.5/data
maxClientCnxns=128
Make sure this above directory exists in the defined folder and have write permissions. If you want to, you can also change the default port from 2181 to something else. I would keep it as is for this example. You can start the Zookeeper by executing below commands
cd ~/testing/zookeeper-3.4.5 bin/zkServer.sh start
Install Apache Hadoop
[~/Downloads] $tar -zxvf hadoop-2.2.0.tar.gz -C ~/testing
Then follow the instructions in this website http://www.alexjf.net/blog/distributed-systems/hadoop-yarn-installation-definitive-guide to configure a Single Node Installation. Make sure you adjust the paths accordingly to your installation paths. For the starting the HDFS, you can use following command instead of multiple executions as shown in the guide.
[~/Downloads] $cd ~/testing/hadoop-2.2.0/ [~/testing/hadoop-2.2.0] $sbin/start-dfs.sh
Make sure there are no errors after you started.
Install Apache Accumulo (For complete installation instructions read README file after the tar file unzipped)
[~/Downloads] $tar -zxvf accumulo-1.5.0-bin.tar.gz -C ~/testing tar -zxvf commons-logging-1.1.3-bin.tar.gz -C ~/testing cp ~/testing/commons-logging-1.1.3/commons-logging-1.1.3.jar ~/testing/accumulo-1.5.0/lib/commons-logging-1.1.3.jar
As part of using Teiid with Accumulo, you need to copy few Teiid java libraries into Accumulo's class path. If for example, if your JBoss AS instance is deployed in "/jboss-eap-6.1" copy the following files to Accumulo's lib directory. Substitute the {version} number in JAR files accordingly to your version of Teiid in use below.
$cp /jboss-eap-6.1/modules/system/layers/base/org/jboss/teiid/translator/accumulo/main/translator-accumulo-{VERSION}.jar lib
$cp /jboss-eap-6.1/modules/system/layers/base/org/jboss/teiid/common-core/main/teiid-common-core-{VERSION}.jar lib
$cp /jboss-eap-6.1/modules/system/layers/base/org/jboss/teiid/client/main/teiid-client-{VERSION}.jar lib
$cp /jboss-eap-6.1/modules/system/layers/base/org/jboss/teiid/api/main/teiid-api-{VERSION}.jar lib
$cp /jboss-eap-6.1/modules/system/layers/base/org/jboss/teiid/main/teiid-engine-{VERSION}.jar lib
$cp /jboss-eap-6.1/modules/system/layers/base/org/jboss/teiid/main/teiid-runtime-{VERSION}.jar lib
$cp /jboss-eap-6.1/modules/system/layers/base/org/jboss/teiid/main/nux-1.6.jar lib
$cp /jboss-eap-6.1/modules/system/layers/base/org/jboss/teiid/main/saxonhe-9.2.1.5.jar lib
Then we need configure it Accumulo before it can be used
[~/Downloads] $cd ~/testing/accumulo-1.5.0/ [~/testing/accumulo-1.5.0] $cp conf/examples/512MB/standalone/* conf [~/testing/accumulo-1.5.0] $vi conf/accumulo-env.sh
add following lines to the "conf/accumulo-env.sh" file on the top (Note: the below may be different paths based on where you installed)
export JAVA_HOME=/usr/java/jdk1.7.0_25 export HADOOP_HOME=~/testing/hadoop-2.2.0 export ZOOKEEPER_HOME=~/testing/zookeeper-3.4.5 export ACCUMULO_HOME=~/testing/accumulo-1.5.0 export HADOOP_CONF_DIR=~/testing/hadoop-2.2.0/etc/hadoop/
Edit the "conf/accumulo-site.xml" file,
- Find "general.classpaths" property, and add the commented lines about Hadoop-2.2.0 library files to the classpath.
- Find "trace.token.property.password" property and choose a password for "root" user and provide it there.
- The port 9999 is used by JBoss AS for management, this is also used by default on Tablet Server. If your JBoss AS and Accumulo on same machine change/add the port property by adding below xml fragment.
<property> <name>master.port.client</name> <value>9995</value> </property>
- save and close.
Before Accumulo can be used, it needs to be initialized. Run the below command
cd ~/testing/accumulo-1.5.0 bin/accumulo init
~/testing/accumulo-1.5.0
The above initialization process asks for "Instance Name", and root password. Instance Name is like database name, choose for example "teiid" and provide same password for root as you choose in the last step. Once this process is finished, you can start Accumulo by executing following command.
bin/start-all.sh
Now we are ready to test all the installation. Execute the following command to open a Accumulo Shell
bin/accumulo -shell -u root
- Now can type 'help', and do various commands including creating tables etc.
- Accumulo set up is now complete. Make sure there were no errors while doing this.
Step 2: Building a VDB
Option 1: Using Teiid Designer (Skip to Option 2 for Dynamic VDB)
- Install Teiid 8.7 (or Later)
- Install Teiid Designer 8.3 or later. Full support for Accumulo may be added in Teiid Designer 8.5 see [TEIIDDES-2065] Add support for Accumulo Translator . With this JIRA resolved you would be able to do import and extension metadata properties available readily.
- Start Teiid Designer, switch to "Teiid Designer" perspective.
- Start JBoss EAP in Teiid profile.
- Configure the Teiid Server, make sure you have made connection to Teiid Server.
- Create a new "Teiid Model Project" and name it "BabyNames".
- We need to create two separate source models, one for the CSV files, and another for the "Accumulo".
- A pre-built sample project "designer_accumulo_project.tar" is attached at the end of this article for your convenience.
Build Flat File based Model
- Choose "File -> import", then choose "Teiid Designer/File Source Flat >> Source and View Model". Follow directions in the article Connect to a Flat File using Teiid to create model based on files. Once you are done a view table like below.
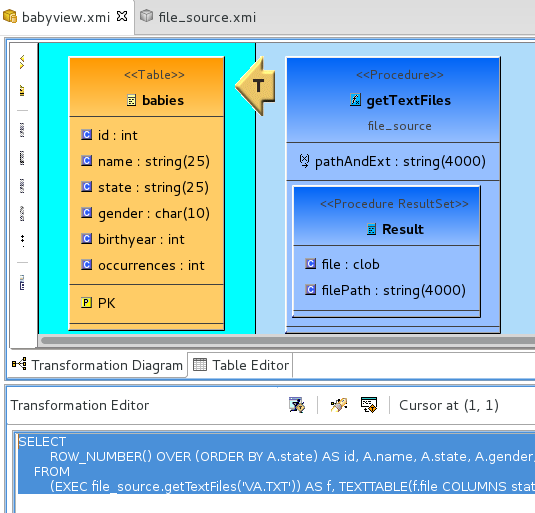
- The transformation of the "babies" view table should look like
SELECT
ROW_NUMBER() OVER (ORDER BY A.state) AS id, A.name, A.state, A.gender, A.birthyear, A.occurrences
FROM
(EXEC file_source.getTextFiles('VA.TXT')) AS f, TEXTTABLE(f.file COLUMNS state string, gender char, birthyear integer, name string, occurrences integer) AS A
- You can preview the data on right clicking on "babies" table, "Modeling -> Preview Data". Make sure this is successful.
Note: The "id" field and PK reference was added after the wizard completed, you do not really need it, but this has been added to completeness sake, you would need to manually tweak the transformation in the view table. In the above ROW_NUMBER is used to generate unique number to be used as PK.
Build Accumulo based Model
- Choose "File -> New", then choose "Teiid Metadata Model", select a name "accumulo", and Model Class: "relational" and Model Type: "Source Model"
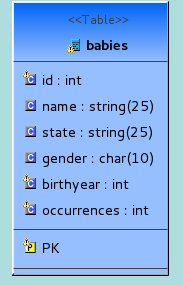
- Then design a table like below. Right Click -> Add Child -> Table then follow the wizard to create the table.
- Alternatively, if you already have data in Accumulo, you can import metadata using "import" and choose "Teiid Connection >> Source Model" type, and choose "accumulo" data source and "accumulo" translator to create a source model. (For this to work successfully TEIID-2065 should have been completed)
Now on each and every column, we need to add extension properties. However as of this writing the Designer is not updated (TEIID-2065) with Acccumulo's extension properties. So, below step you only need to do it before Designer implements TEIID-2065. The below instructions takes you through adding the Model Extension Definitions quickly, however for complete details see Teiid Designer User Guide
- Add "File" -> "New" -> "Teiid Model Extension Defn", choose
- Name Space Prefix: accumulo
- Name Space URI: http://www.teiid.org/translator/accumulo/2013
- Model Class: Relational
- Model Types: Source Model
Now add "Column" based extension properties of below
- CF
- CQ
- VALUE-IN
Now click the tool bar on top of the window, to register this "Model Extension Definition". Then right click on the "accumulo" model created int eh previous step with above babies table, "Modeling" -> "Manage Model Extension Definitions" then choose the name you gave in the previous dialog or "accumulo" if one is already defined.
Now click on each column of the "babies" table, and in the "properties window" in bottom right hand corner, find extension property "CF", and add the column name in there. For example, for 'id' column, the CF property needs to be 'id', for 'name' property the CF property needs to be 'name" and so on. As you may know, in Accumulo, each row is identified with as Column Family, Column Qualifier and timestamp. We are basically configuring with the extension properties, how the columns on this table need to be interpreted by Teiid's Accumulo translator. See following documentation as to what these properties mean and how they are used in the Accumulo translator. Apache Accumulo Translator
Now see in Option 2, how to create Data Sources for File source and Accumulo source or create data sources from Designer for these two sources
Now build a VDB with all the models defined so far, and create data source as shown before and deploy the VDB. Make sure the JNDI names for the sources and translators were assigned correctly. Save, right click on the VDB and choose "modeling->deploy". Make sure the VDB is deployed in "active" state and start testing the SQL interface. On to Step 3
Option 2: Building with Dynamic VDB (Skip this if you did Option 1)
- Edit "standalone-teiid.xml", under "resource-adapter" section add the XML fragments for creation of data sources. Note to adjust ParentDirectory correctly to match where you unzipped the babynames zip file. And Accumulo servers and passwords to match your installation.
Data Source for Flat File
<resource-adapter id="file-ds"> <module slot="main" id="org.jboss.teiid.resource-adapter.file" /> <transaction-support>NoTransaction</transaction-support> <connection-definitions> <connection-definition class-name="org.teiid.resource.adapter.file.FileManagedConnectionFactory" jndi-name="java:/file-ds" enabled="true" pool-name="file-ds"> <config-property name="ParentDirectory">/babynames</config-property> </connection-definition> </connection-definitions> </resource-adapter>
Data Source for Accumulo
<resource-adapter id="accumuloDS"> <module slot="main" id="org.jboss.teiid.resource-adapter.accumulo"/> <transaction-support>NoTransaction</transaction-support> <connection-definitions> <connection-definition class-name="org.teiid.resource.adapter.accumulo.AccumuloManagedConnectionFactory" jndi-name="java:/accumulo-ds" enabled="true" use-java-context="true" pool-name="teiid-accumulo-ds"> <config-property name="ZooKeeperServerList">localhost:2181</config-property> <config-property name="InstanceName">teiid</config-property> <config-property name="Username">user</config-property> <config-property name="Password">password</config-property> </connection-definition> </connection-definitions> </resource-adapter>
- Start JBoss EAP + Teiid Server using command
./standalone.sh -c standalone-teiid.xml
- Create the following dynamic VDB, name the file as "accumulo-babies-vdb.xml". Note that in this VDB we are defining the table definition from Teiid. If data is already in Accumulo, you can also form those tables by automatically reading metadata.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<vdb name="babynames" version="1">
<model name="accumulo">
<source name="node1" translator-name="accumulo" connection-jndi-name="java:/accumulo-ds" />
<metadata type="DDL"><![CDATA[
CREATE FOREIGN TABLE babies (
id integer PRIMARY KEY OPTIONS (SEARCHABLE 'All_Except_Like', "teiid_accumulo:CF" 'id'),
name varchar(25) OPTIONS (SEARCHABLE 'All_Except_Like', "teiid_accumulo:CF" 'name'),
state varchar(25) OPTIONS (SEARCHABLE 'All_Except_Like', "teiid_accumulo:CF" 'state'),
gender char(1) OPTIONS (SEARCHABLE 'All_Except_Like', "teiid_accumulo:CF" 'gender'),
birthyear integer OPTIONS (SEARCHABLE 'All_Except_Like', "teiid_accumulo:CF" 'birthyear'),
occurences integer OPTIONS (SEARCHABLE 'All_Except_Like', "teiid_accumulo:CF" 'occurences')
) OPTIONS (UPDATABLE TRUE)
]]>
</metadata>
</model>
<model name="file_source">
<source name="file" translator-name="file" connection-jndi-name="java:/file-ds" />
</model>
<model name="file" visible="true" type="VIRTUAL">
<metadata type="DDL"><![CDATA[
CREATE VIEW babies (id integer PRIMARY KEY,
name varchar(25),
state varchar(25),
gender char(1),
birthyear integer,
occurences integer
) AS SELECT ROW_NUMBER() OVER (ORDER BY A.state) as id , A.name, A.state, A.gender, A.birthyear, A.occurences FROM
(EXEC file_source.getTextFiles('VA.TXT')) AS f,
TEXTTABLE(f.file COLUMNS state string, gender char, birthyear integer, name string, occurences integer) AS A;
]]>
</metadata>
</model>
</vdb>
- Using either admin-console or CLI, deploy the above VDB. See directions at Deploying VDBs
Step 3: Testing
- Make sure you have active VDB by checking the Console or Log files or by using web-console http://localhost:9990/console/App.html#vdb-runtime
- Now using a tools like SquirreL or Eclipse Data Tools, you can make JDBC connection to "babynames" VDB using JDBC URL"jdbc:teiid:babynames.1@mm://localhost:31000;" and issue SQL queries like below.
Check the records in the File Source
select * from file.babies
Check records in Accumulo Source (Should be none right now)
select * from accumulo.babies
Dump records from File Source into Accumulo
insert into accumulo.babies (id, name, state, gender, birthyear, occurences) select f.id, f.name, f.state, f.gender, f.birthyear, f.occurences from file.babies as f
you should see
(131638 rows affected) Elapsed Time: 0 hr, 1 min, 31 sec, 424 ms.
Now you can issue commands like
select * from accumulo.babies select * from accumulo.babies where name = 'Mary' select * from accumulo.babies where birthyear > 1910 and birthyear < 1920
If you have other models like RDBMS, Salesforce, Web Service etc you can join the table between those sources and Accumulo. You can also issue SQL queries like INESRT/UPDATE/DELETE on Accumulo source to manage the records in the store. For full documentation on Accumulo in Teiid read this documentation Apache Accumulo Translator
Hopefully this article gave how to integrate Accumulo with Teiid. Let us know if you have any comments or suggestions in Teiid forums.
Ramesh..
Comments