In the previous article, I’ve shared some experiences in Hadoop coding with the agile esProc syntax. This article is the supplementary and in-depth discussion based on the previous one.
Firstly, let’t talk about the Cellset Code.
In the previous article, I ‘ve introduced the convenience of using cellset code to define variable, make reference to variable, and achieve the complex computation goal in multiple steps. In facts, the cellset or grid can be used to make it more simple to reuse the computational result. Please refer to the code block below:
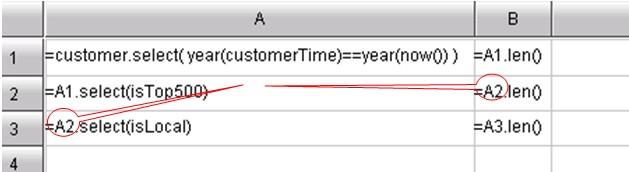
As can be seen, the computational result in A2 is reused in B2 and A3.
The introduction of grid line in the cellset is a good idea. The grid line can keep the code lines aligned naturally, for example, form a clear and intuitive work scope by indentation. Take the below code for example:

Look good. The branch of judgment statement can be recognized well. The code block appears clear and neat without the deliberate edits.
Then, let’s talk about the Object Reference. What is the object reference? Take a previous code snippet for example: A10: =A9. sort(sumAmount: -1). select(#<=10),
The code in A10 can be rewritten in two cells separately, one for sorting, and another for filtering. But in the actual given code, the “,” is used to consolidate the computations of these two steps - this mechanism is referred to as the Object Reference. Object Reference reduces the workload of coding and result in the more agile coding.
Support for direct writing the SQL Statement
The big data computing usually involves the access to Hive database or traditional database. MapReduce requires users to write the complex connect\statement\result statement, while esProc supports direct composing the SQL statement to saves users all these troubles. For example, to get the sales record from the the data source HData of a Hive database, esProc enables users to complete all work with one statement: $(HData)select * from sales.
Function options
Firstly, let’s check out these two statements in the sample code from the first article:
? Code for node machine A2: =A1. groups(${gruopField};${method}(${sumField}): Amount)
? Code for summary machine A9: =A8. groups@o(${gruopField};${method}(Amount): sumAmount)
The former one uses the groups directly to group the unsorted data. The latter one uses the @o option to indicate that the sorted data have been grouped for a much higher speed. @o is a function option to reduce the complex function of heavy workload and make it easier to memorize the names of various functions to achieve different functions. In addition to @o, there are @m and @n function options of the groups function
The function option is a nice design to make the function structure much simpler, and the coding more agile.
Multi-level Parameter
The multi-level parameter (or hierarchy parameter by name) can make the syntax much agile. This is a way to represent the parameters at different levels of the function, for example, ranking the employee by its performance score:
? If the performance score is higher than 90, then set it to “A”
? If the performance score is between 90 and 60, then set it to “B”
? If the performance score is between 60 and 30, then set it to “C”
? If the performance score is below 30, then set it to “D”
In the esProc, the above parameters can be represented like this: score>90:" A",score>60 && score< 90:" B",score>30 && score<=60:" C";"D"
In this case, the parameter can be classified into three levels, and the outermost level: The branch and the default branch is separated with “;”; The middle level: Each branch is separated with “,”; The innermost level: The judgment expressions and results in each branch are separated with “: “. This is a parameter combination of three-level tree structure.
Set-style Grouping
esProc supports the set-style grouping, and is also capable of coding in an agile way. The essence of dynamic data type is the set. Specifically, the simple data type is the set of single value, the array is the set of alike data, and the two dimensional table is the set of records. The member of a set can be another set. Therefore, esProc can be used to represent the concept of grouping in the data computation: Each group is a member of a set, and the member itself is a set. Thanks to the agile syntax, the set-style grouping can be used to solve the complex grouping and computational problems. For example, find the sales person who signed the most and the least insurance policies. The code is as shown below:

A1 cell: Group by sales person. Each group is a set of all policies of one sales person.
A2 cell: Sort the group by the number of policies. In the code snippet, the “~” represents a group of policies corresponding to each sales person.
A3 cell: Find the groups having the most or the least polices. They are the first group and the last group in cell A2.
A4 cell: List the name of sales person. They are the sales persons corresponding to the two groups of policies in A3.
The agile syntax of esProc boosts the efficiency of code development, and reduces the development workload dramatically.