JIRA
This pertains to ISPN-30. It is also related to earlier documents such as this forum thread and JBCACHE-60.
Motivation
To provide a highly scalable mechanism to address a large amount of networked memory in an efficient, transparent and fail-safe manner.
NOTE The designs here have been hastily sketched out as bullet points. While this isn'tthe most readable way to represent such complex ideas, it is a starting point. They will soon be replaced with proper, diagrammatic representations for clarity. Watching this page for changes is recommended.
Design
- ConsistentHash interface
- Implementations of CH contain the logic to deterministically locate a key given a List of Addresses, a key and a replication count. This needs to happen without maintaining any metadata or broadcasting network calls. Efficiency is important. Some approaches and algorithms can be found linked to Wikipedia's article on Consistent Hashing.
- A UnionConsistentHash implementation is also made use of. This is, simply, a delegating implementation that delegates locate calls to 2 different CH instances, and returns an aggregate of results. This is used when new joiners enter a cluster, a rehash is in progress but not as yet completed. More on rehashing later.
- As a requirement for rehashing, positions of caches in a hash space must not change as more cache instances are added. E.g., if in a set of {A, B, C} and a hash space of 1000, A -> 10, B -> 533, C -> 780. The addition of D to the set must never cause the positions of A, B and C to change.
- This does mean that nodes may be unevenly balanced
- But this isn't as big a problem when there is a large number of nodes in the cluster
- Makes rehashing simpler and more performant, so a good tradeoff
- Reading state
- Read requests are tested for whether the key is local to the cache, by consulting the CH instance.
- If the key is not local, the L1 cache is consulted. More on L1 later.
- If the entry is not local and not in L1, a remote GET is performed.
- A remote GET uses the CH to locate the key, and broadcasts a GET request to the owners
- Upon receiving the first valid response, the GET method returns
- If L1 caching is enabled, the entry is stored in L1 with a time-to-live (which is configurable)
- Value returned to user.
- Writing state
- If a return value is required (e.g., Cache.put() returns the old value)
- See if the entry is local (same as in reading state - see above)
- If the entry is not local, check if it is in L1
- If not, perform a remote GET first (see above). This step can be skipped if the Flag.SKIP_REMOTE_LOOKUP flag is used. Warning: while this makes writes more performant, it does imply that return values from put(), etc are unreliable. Only use if you are aware of this fact and don't use the return values of such write commands.
- State updated.
- If the entry is not local and L1 is enabled, the new value is written to L1
- Update broadcast to all addresses the key is mapped to, determined using the CH
- Multicast an invalidation message for the key, to flush from remote L1 caches (if L1 is enabled)
- If a return value is required (e.g., Cache.put() returns the old value)
- Transactions
- All transactional changes are maintained locally in a transaction context
- Performs remote GETs as needed (same as reading state, above)
- Affected key set is maintained for teh entire transaction
- On prepare, a set of affected nodes is determined by applying the CH to the set of affected keys
- Prepare is broadcast to all affected nodes
- Receiving nodes only apply writes that pertain to them.
- E.g., Tx1 may span k1, k2, k3. k1 -> {N1, N2}, k2 -> {N3, N4}, k3 -> {N5, N6}.
- The prepare is sent to all {N1, N2, N3, N4, N5, N6}.
- N1 should only apply writes for k1. Not k2 and k3. Again determined using the CH.
- Receiving nodes only apply writes that pertain to them.
- Commit/rollback again sent to all affected nodes.
- L1 Caches
- L1 is a local, near cache to prevent multiple remote lookups for GETs
- Can be optionally disabled
- Enabled by default
- Uses a time-to-live, regardless of the actual TTL on the entry
- Invalidated when the entry is modified using a multicast
- Rehashing
- NB: This is complex and adds a lot of overhead. As far as possible, joins/leaves should be done in a controlled manner (e.g., try and stagger joins, after allowing time for rehashing to complete, etc).
- Relies on RPC commands to push and pull state. In future this can be improved using streams. (See section on improvements below)
- JOIN process
- Only one joiner at a time is allowed. Coordinated by the coordinator.
- Joiner requests for permission to join - my contacting the coordinator. This permission request involves the coordinator sending the joiner the cluster topology that existed before the joiner joined.
- If permission is not granted, the joiner waits and tries again later.
- Joiner enables transaction logging, to log incoming writes. (Similar to non-blocking state transfer for REPL)
- Remote reads are responded to with an UnsureResponse, prompting the caller to consult the next available data owner.
- In line with eventual consistency concepts. Callers should make sure a definite SuccessfulResponse is used rather than an UnsureResponse.
- Joiner multicasts to the cluster informing of a rehash in progress.
- All caches update their CH with a UnionCH - which delegates to the old CH and a new one that includes the joiner.
- joiner then calculates who may send it state, based on the old cluster topology.
- Given a list of nodes {N1 .. Nx}, including the joiner:
- locate the index of the joiner in this list - iJ
- Nodes that would possibly send state include nodes at positions {iJ - replCount + 1 .. iJ - 1, iJ + 1}
- Send a state PULL request (RPC) to these nodes
- Nodes that receive the PULL request loop through all keys in their data containers (and non-shared cache stores), identifying keys that should be sent to the joiner - by consulting the CH. Entries added to a response map.
- This happens in parallel. We do not wait for all responses before we start applying stuff.
- Once received all responses, joiner applies this state
- Joiner broadcasts an invalidate message to all nodes that the keys may have mapped to (again using the CH) to ensure unnecessary copies are not maintained.
- Joiner informs all nodes (multicast) that it has completed rehashing
- Joiner drains tx log and disables tx logging.
- Remote writes go straight to the underlying data container from now on.
- Joiner informs coordinator that the join process is complete, thus allowing other joiners to start.
- LEAVE process: more involved than a JOIN!
- Each node maintains a concurrent list of leavers (LL).
- When a leave is detected:
- Update CH (and any UnionCH) to remove the leaver. Make a copy of the old version of the CH first though.
- Determine if the node is affected by the leave.
- This is calculated by locating the position of the leaver (L), and if L is adjacent (+ or - 1 in position) then:
- L is added to LL
- If an existing LeaveTask is in progress, cancel it
- Start a LeaveTask
- If the node is in L + or - replCount, then start tx logging for changes, and respond to read requests with an UnsureResponse. NB this may not be necessary for such a wide range of nodes - needs a bit more thought. A bit pessimistic and heavy handed for now
- This is calculated by locating the position of the leaver (L), and if L is adjacent (+ or - 1 in position) then:
- LeaveTask
- Looping thru all state and see if it included anyone in LL
- If so, determine whether it is the current node's responsibility to handle the rehash for this entry.
- foreach L in LL:
- if L is last in the list of CH-determined locations and current is last-1 OR
- if L is NOT last in the list of CH-determined locations and current is L +1
- foreach L in LL:
- Find new owners for key
- Create (or add to) a state map for all new owners that were not old owners as well
- If so, determine whether it is the current node's responsibility to handle the rehash for this entry.
- Push state maps to respective recipients
- Happens in parallel
- Each node that receives state then drains its txLog and switches off tx logging
- Invalidate on nodes that would no longer own keys pushed (NB: This step may be unnecessary and overly pessimistic. Needs thought)
- Looping thru all state and see if it included anyone in LL
Improvements
Some areas that could (and probably will) be improved on in future (after a lot more thought and discussion) include:
- Stream-based transfer of state (rather than RPC)
- This will improve performance (no unnecessary marshalling/unmarshalling of cache store state for example)
- Deal with large state better
- Use of virtual nodes in the hash space
- Allows for more even spread of load across nodes
- Allows for optional biasing and weighting
- More optimistic approach to handling leavers
- Ability to handle multiple concurrent JOINs
- Remove the need for multicasting join stage
Implementation notes
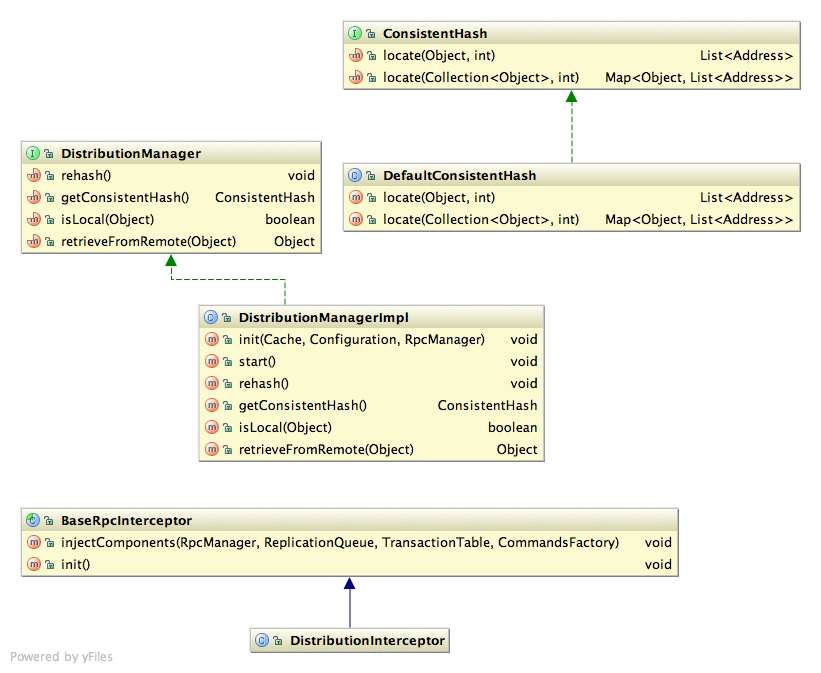
- DistributionInterceptor used instead of ReplicationInterceptor.
- All remote RPC calls are sent to a subset of the cluster, identified by ConsistentHash.locate().
- If an L1 cache is configured, the DI also broadcasts an invalidate command to all else in the cluster
- If a node is an "owner" of the key, the invalidate command should be ignored.
- Determined by DistributionManager.isLocal()
- DistributionManager should listen for view change events and kicks off either a JoinTask (if joiner) or a LeaveTask (if affected; see designs above)
- JoinTask and LeaveTask are subclasses of RehashTask, which is a Callable. Submitted to a low-prio ExecutorService
- Configuration elements include:
- L1 cache enabled
- L1 lifespan
- rehash wait time
- ConsistentHash impl
- number of data owners
- On rehash, whether entries are removed or moved to L1 (only if L1 is enabled)
<clustering mode="distribution">
<!-- dist and d are also synonyms, just as repl and r are synonyms for replication -->
<hash class="org.infinispan.distribution.DefaultConsistentHash" numOwners="2" rehashWait="60000" />
<l1 enabled="true" lifespan="600000" onRehash="true" />
</clustering>
Return values
The public API makes use of return values, for methods such as put(), remove(), replace() and their overloaded counterparts. If the method is invoked on a cache where the data is not resident (or is not in L1), it would require the return value being retrieved from the remote cache where the call is executed. While this can be unnecessarily expensive (additional remote call!) it can be disabled by using the Flag.SKIP_REMOTE_LOOKUP flag. Note though that while this does improve performance, it will render any return values from such methods as unreliable and useless. Only use this flag if you know the return values of such calls are not used.
Legacy designs
Prior to Infinispan, some old designs around partitioning were noted down here: JBoss Cache - Partitioning
Comments